Machine learning (ML) and other artificial intelligence (AI) algorithms are increasingly being adopted across previously human-restricted fields, including medicine, military, education, and scientific research. With recent advancements in computing power and the development of 'smarter' AI models, these deep learning algorithms are now widely used in clinical neurology for tasks ranging from neurological diagnosis to treatment and prognosis.
Recently, transformer-based AI architectures – AI algorithms trained on extensive data sets of 45 terabytes or more – are aiding and sometimes even replacing humans in traditionally solely human roles, including neurology. The vast amount of training data, in tandem with continuously improved code, allows these models to present responses, suggestions, and predictions that are both logical and accurate. Two main algorithms based on the popular ChatGPT platform have hitherto been developed – LLM 1 (ChatGPT version 3.5) and LLM 2 (ChatGPT 4). The former is computationally less demanding and much more rapid in its data processing, while the latter is contextually more accurate.
Even though informal evidence is in favor of the usefulness of these models, their performance and accuracy have rarely been tested in a scientific setting. The limited existing evidence comes from research into the performance of LLM 1 in the United States Medical Licensing Examination (USMLE) and in ophthalmology examinations, with LLM 2 version being hitherto unvalidated.
About the study
In the present study, researchers aimed to compare the performance of LLM 1 and 2 against human neurology students in board-like written examinations. This cross-sectional study complies with the Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) guidelines and uses a neurology board examination as a proxy for LLM 1 and 2's performance in highly technical human medical examinations.
The study used questions from the publicly available American Board of Psychiatry and Neurology (ABPN) question bank. The bank contains 2,036 questions, of which 80 were excluded due to their being based on presented videos or images. LLM 1 and LLM 2 were obtained from server-contained online sources (ChatGPT 3.5 and 4, respectively) and were trained until September 2021. Human comparisons were made using actual data from previous iterations of the ABPN board entrance examination.
Notably, during evaluations, pre-trained models LLM 1 and 2 did not have access to online resources to verify or improve their answers. No neurology-specific model tweaking or fine-tuning was carried out prior to model testing. The testing process comprised subjecting the models to 1,956 multiple-choice questions, each with one correct answer and between three and five distractors. All questions were classified as lower-order (basic understanding and memory) and higher-order (application, analysis, or evaluative-thinking-based) questions following the Bloom taxonomy for learning and assessment.
Evaluation criteria considered a score of 70% or higher as the minimum passing grade for the examination. Models were tested for answer reproducibility via 50 independent queries designed to probe principles of self-consistency.
"For the high-dimensional analysis of question representations, the embeddings of these questions were analyzed. These numeric vector representations encompass the semantic and contextual essence of the tokens (in this context, the questions) processed by the model. The source of these embeddings is the model parameters or weights, which are used to code and decode the texts for input and output."
Statistical analysis consisted of a single-variable, order-specific comparison between models' performance and previous human results using a chi-squared (χ2) test (with Bonferroni corrections for 26 identified question subgroups).
Study findings
LLM 2 showed the best performance of all tested cohorts, obtaining a score of 85.0% (1662 out of 1956 questions answered correctly). In comparison, LLM 1 scored 66.8%, and humans averaged 73.8%. Model performance was found to be highest in lower-order questions (71.6% and 88.5%, respectively, for models 1 and 2).
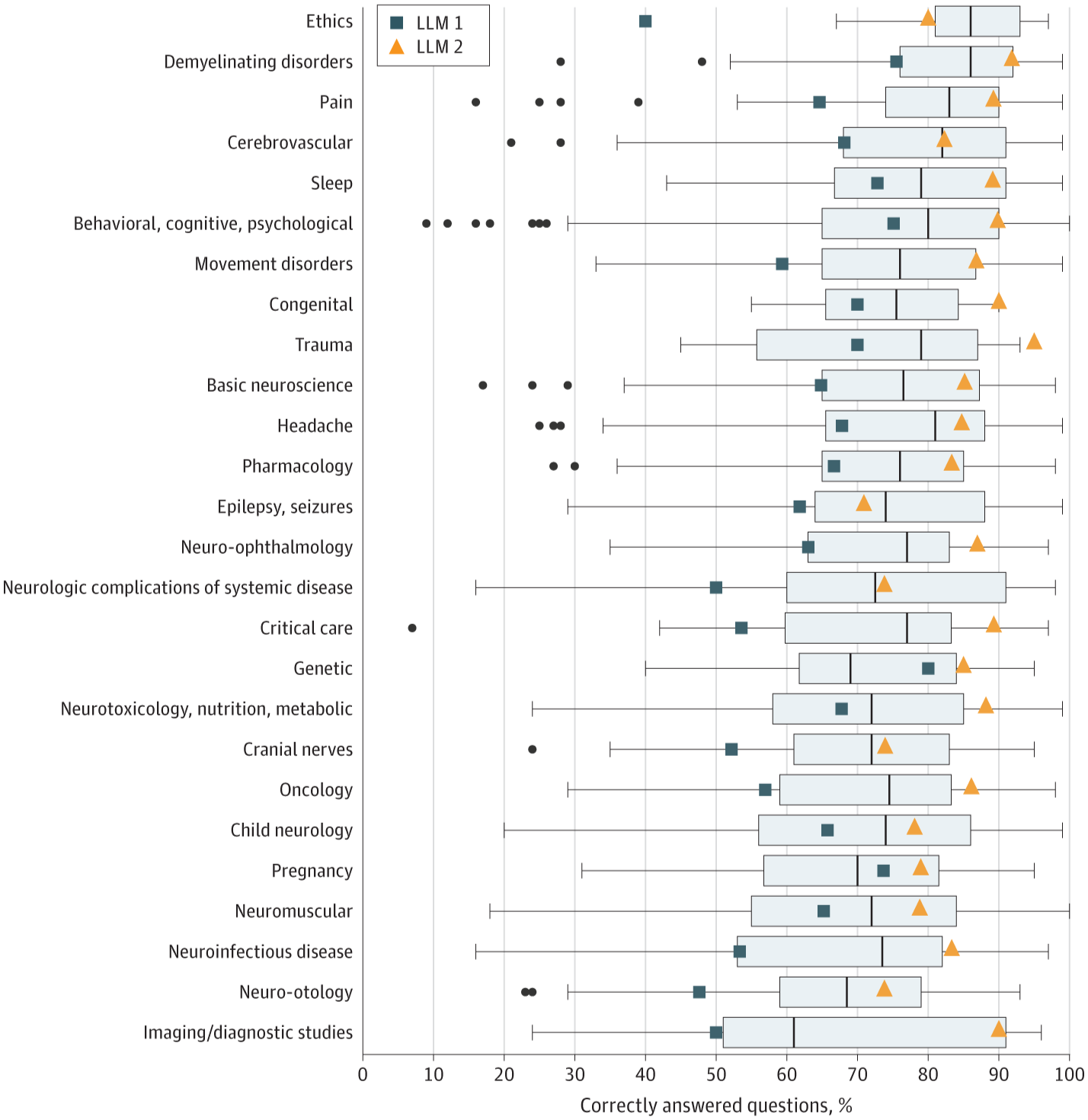 Boxplots illustrate human user score distribution, with the black line indicating the median, the edges of the boxes indicating first and third quartiles, and the whiskers indicating the largest and smallest value no further than 1.5 × IQR from the lower and upper edges. Dots indicate outliers. LLM indicates large language model.
Boxplots illustrate human user score distribution, with the black line indicating the median, the edges of the boxes indicating first and third quartiles, and the whiskers indicating the largest and smallest value no further than 1.5 × IQR from the lower and upper edges. Dots indicate outliers. LLM indicates large language model.
Interestingly, LLM 1's lower-order accuracy was similar to that of human students (71.6% versus 73.6%) but significantly lower for higher-order questions (62.7% versus 73.9%). Just half a generation later, however, algorithm improvements allowed ChatGPT version 4 to outcompete human students in both lower- and higher-order accuracy.
"In the behavioral, cognitive, psychological category, LLM 2 outperformed both LLM 1 and average test bank users (LLM 2: 433 of 482 [89.8%]; LLM 2: 362 of 482 [75.1%]; human users: 76.0%; P < .001). LLM 2 also exhibited superior performance in topics such as basic neuroscience, movement disorders, neurotoxicology, nutrition, metabolic, oncology, and pain compared with LLM 1, whereas its performance aligned with the human user average"
Conclusions
In the present study, researchers evaluated the performance of two ChatGPT LLMs in neurological board examinations. They found that the later model significantly outperformed both the earlier model, and human neurology students across lower- and higher-order questions. Despite showing greater strengths in memory-based questions compared to those requiring cognition, these results highlight these models' potential in aiding or even replacing human medical experts in non-mission-critical roles.
Notably, these models were not tweaked for neurological purposes, nor were they allowed access to constantly updating online resources, both of which could further improve the performance gains between them and their human creators. In a nutshell, AI LLMs are getting smarter at an unprecedented pace.
On a jovial note, the author of this article (who has no affiliation with the study authors) recommends that the time-traveling cyborgs are prepared for rapid deployment as a safeguard if and when the LLMs realize how smart they are!
 Blood pressure control may be the key to optimizing stroke treatment after thrombectomy
Blood pressure control may be the key to optimizing stroke treatment after thrombectomy