Initially, all the information needed to make medical decisions is highly scattered, e.g., in a patient's medical records, including their prescriptions, laboratory, and imaging reports. Physicians aggregate all the relevant information from this pool of information into handwritten notes, which document and summarize patient care.
Existing clinical predictive models rely on structured inputs retrieved from the patient EHRs or clinician inputs, complicating data processing, model development, and deployment. As a result, most medical predictive models are trained, validated, and published, yet never used in real-world clinical settings, often considered the 'last-mile problem'.
On the other hand, artificial intelligence (AI)-based large language models (LLMs) rely on reading and interpreting human language. Thus, the researchers theorized that LLMs could read handwritten physician notes to solve the last-mile problem. In this way, these LLMs could facilitate medical decision-making at the point of care for a broad range of clinical and operational tasks.
About the study
In the present study, researchers leveraged recent advances in LLM-based systems to develop NYUTron and prospectively assessed its efficacy in performing five clinical and operational predictive tasks, as follows:
- 30-day all-cause readmission
- in-hospital mortality
- comorbidity index prediction
- length of stay (LOS)
- insurance denial prediction
Further, the researchers performed a detailed analysis on readmission prediction, i.e., the likelihood of a patient seeking readmission to the hospital within 30 days of discharge due to any reason. Specifically, they performed five additional evaluations in retrospective and prospective settings; for instance, the team evaluated NYUTron's scaling properties and compared them with other models using several fine-tuned data points.
In retrospective evaluations, they head-to-head compared six physicians at different levels of seniority against NYUTron. In prospective evaluations running between January and April 2022, the team tested NYUTron in an accelerated format. They loaded it into an inference engine which interfaced with the EHR and read discharge notes duly signed by treating physicians.
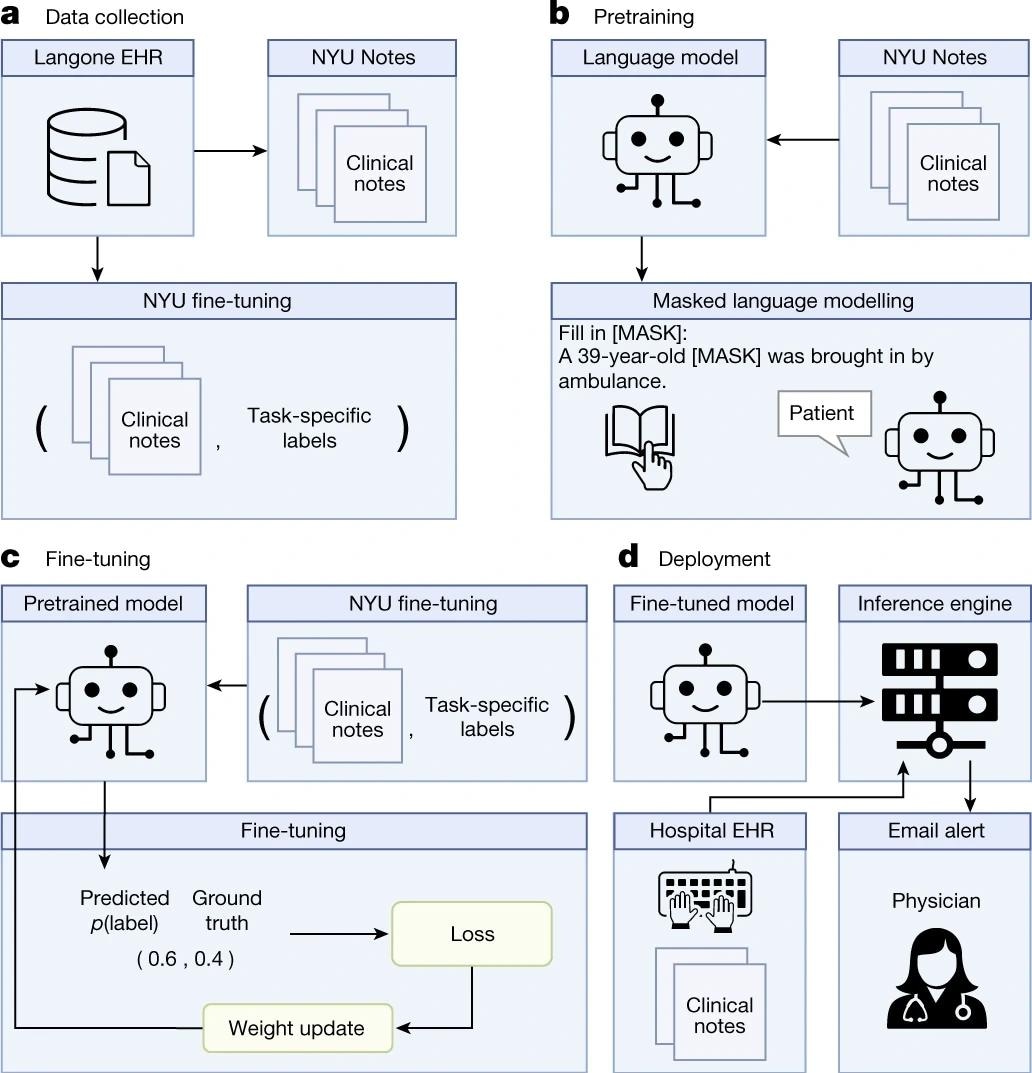
a, We queried the NYU Langone EHR for two types of datasets. The pretraining dataset, NYU Notes, contains 10 years of inpatient clinical notes (387,144 patients, 4.1 billion words). There are five fine-tuning datasets. Each contains 1–10 years of inpatient clinical notes (55,791–413,845 patients, 51–87 million words) with task-specific labels (2–4 classes). b, We pre-trained a 109 million-parameter BERT-like LLM, termed NYUTron, on the entire EHR using an MLM task to create a pretrained model for medical language contained within the EHR. c, We subsequently fine-tuned the pre-trained model on specific tasks (for example, 30-day all-cause readmission prediction) and validated it on held-out retrospective data. d, Lastly, the fine-tuned model was compressed into an accelerated format and loaded into an inference engine, which interfaces with the NYU Langone EHR to read discharge notes when they are signed by treating physicians.
Results
Compared to prior conventional models, NYUTron had an overall area under the curve (AUC) ranging between 78.7 and 94.9%, i.e., an improvement of up to 14.7% concerning AUC. Additionally, the authors demonstrated the benefits of pretraining NYUTron with clinical text, which increased its generalizability through fine-tuning and eventually enabled its full deployment in a single-arm, prospective trial.
Readmission prediction is a well-studied task in the published literature on medical informatics. In its retrospective evaluation, NYUTron performed better than a physician, with a median false positive rate (FPR) of 11.11% for both NYUTron and the physician. However, the median true positive rate (TPR) was higher for NYUTron than physicians, 81.72% vs. 50%.
In its prospective evaluation, NYUTron predicted 2,692 of the 3,271 readmissions (82.30% recall) with 20.58% precision, with an AUC of 78.7%. Next, a panel of six physicians randomly evaluated 100 readmitted cases captured by NYUTron and found that some predictions by NYUTron were clinically relevant and could have prevented readmissions.
Intriguingly, 27 NYUTron predicted readmissions were preventable, and patients predicted to be readmitted were six times more likely to die in the hospital. Also, three of the 27 preventable readmissions had enterocolitis, a bacterial infection frequently occurring in hospitals by Clostridioides difficile. Notably, it results in the death of one in 11 infected people aged >65.
The researchers used 24 NVIDIA A100 GPUs with 40 GB of VRAM for three weeks for pretraining NYUTron, and eight A100 GPUs for six hours per run for fine-tuning. Generally, this amount of computation is inaccessible to researchers. However, the study data demonstrated that high-quality datasets for fine-tuning were more valuable than pretraining. Based on their experimental results, the authors recommended that users use local fine-tuning when their computational ability is limited.
Furthermore, in this study, the researchers used decoder-based architecture, e.g., bidirectional encoder representation with transformer (BERT), demonstrating the benefits of fine-tuning medical data, emphasizing the need for domain shift from general to medical text for LLM research.
Conclusions
To summarize, the current study results suggested the feasibility of using LLMs as prediction engines for a suite of medical (clinical and operational) predictive tasks. The authors also raised that physicians could over-rely on NYUTron predictions, which, in some cases, could lead to lethal consequences, a genuine ethical concern. Thus, the study results highlight the need to optimize human–AI interactions and assess sources of bias or unanticipated failures.
In this regard, researchers recommended different interventions depending on the NYUTron-predicted risk for patients. For example, follow-up calls are adequate for a patient at low risk of 30-day readmission; however, premature discharge is a strict 'NO' for patients at high risk. More importantly, while operational predictions could be automated entirely, all patient-related interventions should be implemented strictly under a physician's supervision. Nonetheless, LLMs present a unique opportunity for seamless integration into medical workflows, even in large healthcare systems.
 New trial shows oral therapy increases growth in children with achondroplasia
New trial shows oral therapy increases growth in children with achondroplasia