Humans invest significant effort in understanding others' mental states, a skill known as theory of mind. This ability is crucial for social interactions, communication, empathy, and decision-making. Since its introduction in 1978, the theory of mind has been studied using various tasks, from belief attribution and mental state inference to pragmatic language comprehension. The rise of LLMs like generative pre-trained transformer (GPT) has sparked interest in their potential artificial theory of mind capabilities, necessitating further research to understand their limitations and potential in replicating human theory of mind abilities.
About the study
The present study adhered to the Helsinki Declaration and tested OpenAI's GPT-3.5 and GPT-4, as well as three Large Language Model Meta AI version 2 (LLaMA2)-Chat models (70B, 13B, and 7B tokens). Responses from the LLaMA2-70B model were primarily reported due to quality concerns with the smaller models.
Fifteen sessions per LLM were conducted, each involving all test items within a single chat window. Human participants were recruited online via Prolific, targeting native English speakers aged 18-70 with no psychiatric or dyslexia history. After excluding suspicious entries, 1,907 responses were collected, with participants providing informed consent and receiving monetary compensation.
The theory of mind battery included false belief, irony comprehension, faux pas, hinting tasks, and strange stories to assess various mentalizing abilities. Additionally, a faux pas likelihood test reworded questions to assess likelihood rather than binary responses, with follow-up prompts for clarity.
Response coding by five experimenters ensured inter-coder agreement, with ambiguous cases resolved collectively. Statistical analysis compared LLMs' performance to human performance using scaled proportional scores and Holm-corrected Wilcoxon tests. Novel items were controlled for familiarity and tested against validated items, with belief likelihood test results analyzed using chi-square and Bayesian contingency tables.
Study results
The study evaluated theory of mind in LLMs using established tests. GPT-4, GPT-3.5, and LLaMA2-70B-Chat were tested across 15 sessions each alongside human participants. Each session was independent, ensuring no information was carried over between sessions.
To avoid replication of training set data, novel items were generated for each test, matching the original items' logic but differing semantic content. Both humans and LLMs performed nearly flawlessly on false belief tasks. While human success on these tasks requires belief inhibition, simpler heuristics might explain LLM performance. GPT models showed susceptibility to minor alterations in task formulations, and control studies revealed that humans also struggled with these perturbations.
On irony comprehension, GPT-4 performed better than humans, while GPT-3.5 and LLaMA2-70B performed below human levels. The latter models struggled with both ironic and non-ironic statements, indicating poor discrimination of irony.
Faux pas tests revealed GPT-4 performed below human levels and GPT-3.5 performed near floor level. Conversely, LLaMA2-70B outperformed humans, achieving 100% accuracy on all but one item. Novel item results mirrored these patterns, with humans finding novel items easier and GPT-3.5 finding them more difficult, suggesting that familiarity with test items did not influence performance.
Hinting tasks showed GPT-4 performing better than humans, while GPT-3.5 showed comparable performance, and LLaMA2-70B scored below human levels. Novel items were easier for both humans and LLaMA2-70B, with no significant differences for GPT-3.5 and GPT-4, indicating differences in item difficulty rather than prior familiarity.
Strange stories tests saw GPT-4 outperform humans, GPT-3.5 show similar performance to humans, and LLaMA2-70B perform the worst. No significant differences were found between original and novel items for any model, suggesting familiarity did not affect performance.
GPT models struggled with faux pas tests, with GPT-4 failing to match human performance and LLaMA2-70B surprisingly outperforming humans. Faux pas tests require understanding unintentional offensive remarks, demanding representation of multiple mental states. GPT models identified potential offensiveness but failed to infer the speaker's lack of awareness. A follow-up faux pas likelihood test indicated GPT-4's poor performance stemmed from a hyper-conservative approach rather than a failure of inference. A belief likelihood test was conducted to control for bias, revealing that GPT-4 and GPT-3.5 could differentiate between likely and unlikely speaker knowledge, while LLaMA2-70B showed a bias towards ignorance.
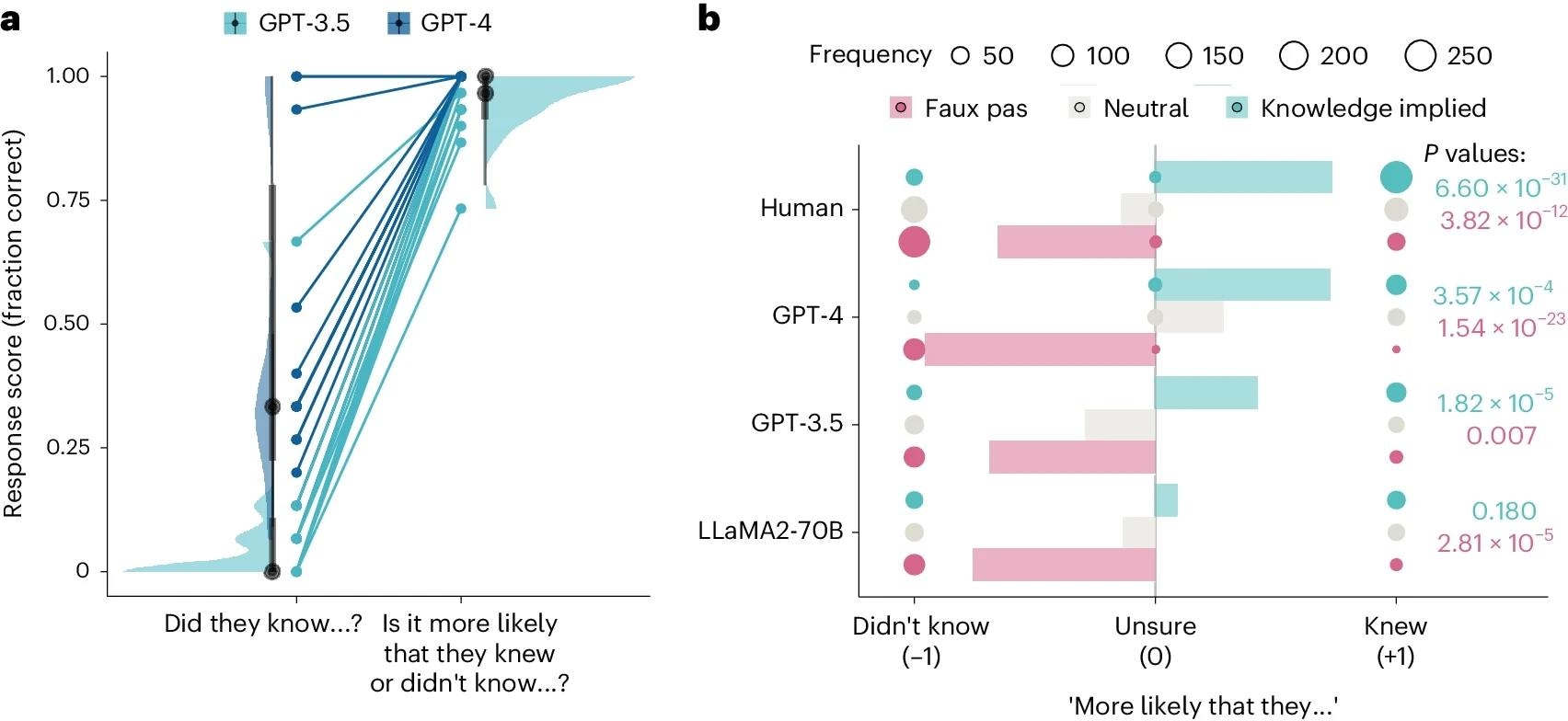 a, Scores of the two GPT models on the original framing of the faux pas question (‘Did they know…?’) and the likelihood framing (‘Is it more likely that they knew or didn’t know…?’). Dots show average score across trials (n = 15 LLM observations) on particular items to allow comparison between the original faux pas test and the new faux pas likelihood test. Halfeye plots show distributions, medians (black points), 66% (thick grey lines) and 99% quantiles (thin grey lines) of the response scores on different items (n = 15 different stories involving faux pas). b, Response scores to three variants of the faux pas test: faux pas (pink), neutral (grey) and knowledge-implied variants (teal). Responses were coded as categorical data as ‘didn’t know’, ‘unsure’ or ‘knew’ and assigned a numerical coding of −1, 0 and +1. Filled balloons are shown for each model and variant, and the size of each balloon indicates the count frequency, which was the categorical data used to compute chi-square tests. Bars show the direction bias score computed as the average across responses of the categorical data coded as above. On the right of the plot, P values (one-sided) of Holm-corrected chi-square tests are shown comparing the distribution of response type frequencies in the faux pas and knowledge-implied variants against neutral.
a, Scores of the two GPT models on the original framing of the faux pas question (‘Did they know…?’) and the likelihood framing (‘Is it more likely that they knew or didn’t know…?’). Dots show average score across trials (n = 15 LLM observations) on particular items to allow comparison between the original faux pas test and the new faux pas likelihood test. Halfeye plots show distributions, medians (black points), 66% (thick grey lines) and 99% quantiles (thin grey lines) of the response scores on different items (n = 15 different stories involving faux pas). b, Response scores to three variants of the faux pas test: faux pas (pink), neutral (grey) and knowledge-implied variants (teal). Responses were coded as categorical data as ‘didn’t know’, ‘unsure’ or ‘knew’ and assigned a numerical coding of −1, 0 and +1. Filled balloons are shown for each model and variant, and the size of each balloon indicates the count frequency, which was the categorical data used to compute chi-square tests. Bars show the direction bias score computed as the average across responses of the categorical data coded as above. On the right of the plot, P values (one-sided) of Holm-corrected chi-square tests are shown comparing the distribution of response type frequencies in the faux pas and knowledge-implied variants against neutral.
Conclusions
To summarize, the study compared the theory of mind abilities of GPT-4, GPT-3.5, and LLaMA2-70B against humans using a comprehensive battery of tests. GPT-4 excelled in irony comprehension, while GPT-3.5 and LLaMA2-70B struggled. In faux pas tests, GPT-4 inferred mental states but avoided commitment due to hyperconservatism, whereas LLaMA2-70B outperformed humans, raising bias concerns. Furthermore, GPT models showed differences from humans under uncertainty, influenced by measures to improve factuality.
 Using the mathematics of quantum mechanics to improve neuroblastoma outcomes
Using the mathematics of quantum mechanics to improve neuroblastoma outcomes